Avoiding Integration Bugs: Beyond SDKs & Contract Testing

You're working at a fast-moving startup. Speed is everything. You refactor an API, update the consumers you know about, ship it... and then Slack explodes. An obscure downstream service you didn't even know existed (or forgot about) just fell over in production because it was relying on the old API format. Or maybe you changed a database column, and the analytics pipeline choked horribly three hours later. Sound familiar?
In the world of distributed systems, integration points are the fault lines where things most often break, especially when teams are moving fast. Breaking changes happen. The challenge isn't just fixing them; it's preventing them from ever reaching production. While tools like Typed SDKs and Contract Testing offer valuable safety nets, they often leave dangerous gaps. We need to shift further left and gain proactive, system-wide awareness.
The High Cost of Broken Integrations: More Than Just Downtime
Let's get specific about the pain –
Scenario 1: The Missed Consumer
Your UserService proudly renames the user_email field to the much clearer emailAddress. You diligently update the OrderService and NotificationService, the main consumers you remembered. But deep in the codebase lurks a legacy ReportingService, built by a team long gone, that also consumed user_email. It breaks silently on the next deployment, only discovered when month-end reports fail catastrophically. Cue frantic debugging and emergency hotfixes.
Scenario 2: The Database Ripple Effect
The ProductService team smartly decides to change the price column in their database from a potentially imprecise string to a proper decimal type. They update their own service logic. Unfortunately, a downstream analytics service reads directly from a database replica. Its ETL jobs crash hard on the next run, unable to parse the new data type. The data warehouse is now stale, and critical business reports are wrong.
Scenario 3: The Deployment Race Condition
AuthService deploys a critical security update requiring a new token format (a breaking change). They notified other teams, and the APIService team prepared the necessary update. But AuthService deploys at 2:00 PM, and due to a hiccup, APIService deploys its fix at 2:05 PM. For five crucial minutes, every single user login attempt fails.
The impact isn't just downtime. It's lost revenue, potentially corrupted data, wasted engineering hours firefighting instead of building features, and a creeping erosion of trust between teams ("Did they break us again?").
So how can we defend against these issues?
Defense Layer 1: Typed Client SDKs (Code Generation Magic)
Tools like TRPC (for TypeScript) or code generators based on OpenAPI/Swagger schemas promise type safety across API boundaries.
How it Works: Define your API schema, generate a client library. Consumers import the client and (ideally) get compile-time errors if they misuse the API (e.g., pass the wrong type, access a renamed field).
Pros: Fantastic developer experience within a compatible language ecosystem (e.g., fullstack TypeScript). Catches basic structural mismatches early. Autocomplete goodness.
Cons: The dream often crumbles in polyglot environments (how does your Python service easily consume that generated TypeScript client?). Relies heavily on keeping schemas perfectly up-to-date and regenerating clients religiously. Usually only catches structural breaks, not subtle semantic or behavioral changes. Adds build tooling complexity.
Here's an example of what this might look like in practice:
In @org/user-api package:
// 1. Define your API schema (this could be in OpenAPI/Swagger format too)
// userService.schema.ts
export interface User {
id: string;
emailAddress: string; // Previously was user_email
firstName: string;
lastName: string;
createdAt: Date;
}
// 2. Generate the client SDK
// userServiceClient.ts
export class UserServiceClient {
private baseUrl: string;
private headers: Record<string, string>;
constructor(baseUrl: string, apiKey: string) {
this.baseUrl = baseUrl;
this.headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`
};
}
async getUser(userId: string): Promise<User> {
const response = await fetch(`${this.baseUrl}/users/${userId}`, {
method: 'GET',
headers: this.headers
});
if (!response.ok) {
throw new Error(`Failed to fetch user: ${response.statusText}`);
}
return response.json() as Promise<User>;
}
async createUser(user: Omit<User, 'id' | 'createdAt'>): Promise<User> {
const response = await fetch(`${this.baseUrl}/users`, {
method: 'POST',
headers: this.headers,
body: JSON.stringify(user)
});
if (!response.ok) {
throw new Error(`Failed to create user: ${response.statusText}`);
}
return response.json() as Promise<User>;
}
async updateUser(userId: string, userData: Partial<Omit<User, 'id' | 'createdAt'>>): Promise<User> {
const response = await fetch(`${this.baseUrl}/users/${userId}`, {
method: 'PATCH',
headers: this.headers,
body: JSON.stringify(userData)
});
if (!response.ok) {
throw new Error(`Failed to update user: ${response.statusText}`);
}
return response.json() as Promise<User>;
}
}
and usage:
import { UserServiceClient } from './userServiceClient';
class OrderService {
private userClient: UserServiceClient;
constructor(userServiceBaseUrl: string, apiKey: string) {
this.userClient = new UserServiceClient(userServiceBaseUrl, apiKey);
}
async createOrder(userId: string, items: any[]): Promise<any> {
// Get the user to associate with the order
const user = await this.userClient.getUser(userId);
// With typed SDK, this would be a type error if the field was renamed
console.log(`Creating order for ${user.emailAddress}`);
// Rest of order creation logic...
return {
orderId: 'ord_' + Math.random().toString(36).substr(2, 9),
userId: user.id,
customerEmail: user.emailAddress,
items
};
}
}More succinctly:
// This would cause TypeScript error:
// Property 'user_email' does not exist on type 'User'.
// Did you mean 'emailAddress'?
function badConsumer(user: User) {
return user.user_email; // ❌ Compile-time error
}
// This works fine:
function goodConsumer(user: User) {
return user.emailAddress; // ✅ Safe
}Defense Layer 2: Contract Testing (Consumer-Driven Verification)
Frameworks like Pact flip the script: the consumer defines how it expects to interact with the provider (the requests it will send, the responses it expects).
How it Works: The consumer generates a "contract" file during its tests. The provider runs this contract against its code in its own CI pipeline to ensure it fulfills the consumer's expectations.
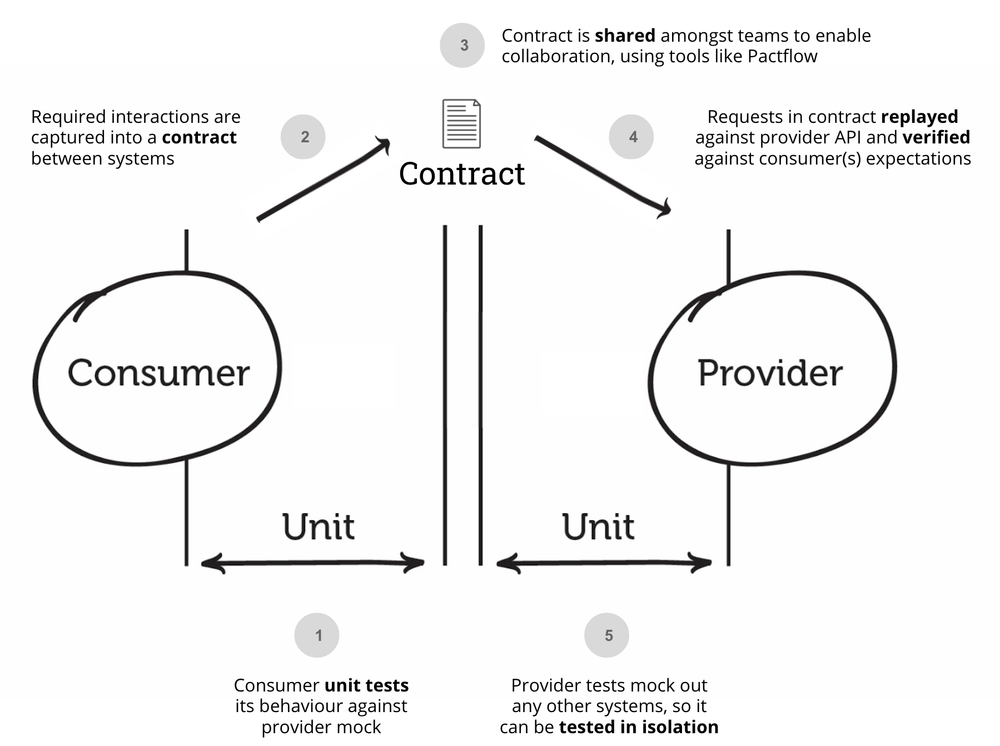
Pros: Language agnostic (contracts are usually JSON). Verifies interactions based on actual consumer needs. Shifts verification earlier (to the provider's CI).
Cons: Requires significant buy-in, coordination, and discipline across teams. Setup and maintenance of the contract testing framework can be non-trivial. Primarily tests known consumer-provider pairs – it won't find that forgotten ReportingService. Doesn't inherently prevent deploying incompatible versions simultaneously if CI passes for both independently.
Defense Layer 3: Integration Testing (Catching Failures at the Boundaries)
While Client SDKs and Contract Testing create safety within controlled environments, Integration Testing simulates the chaos of the real world where multiple services interact in complex ways.
How it Works: Unlike unit tests or mocked contract tests, integration tests spin up actual instances of your services—connecting to test databases, message queues, and dependencies—and exercise complete user journeys across system boundaries.
A robust integration test setup might look like this:
- Spin up containerized versions of UserService, OrderService, and PaymentService connected to isolated test databases.
- Trigger a complete user flow: register user → browse products → add to cart → checkout → receive confirmation.
- Verify that the end-to-end journey works AND that the data is consistent across all service boundaries.
Pros: Tests the "real thing" under conditions that more closely resemble production. Catches intricate timing issues, race conditions, and subtle integration bugs that mock-based tests miss. Creates confidence in complex workflows that span multiple services.
Cons: Significantly more complex to set up and maintain than contract tests. Can be brittle and slow to run. Often catches issues late in the development cycle (after individual services are built). May miss problems that only occur at production scale or with specific production data patterns.
Defense Layer 4: Proactive Impact Analysis (System-Wide Foresight with Nimbus)
What if you could know the entire blast radius of a change before you even merge the code, let alone deploy it? This is the promise of proactive impact analysis.
How it Works: Instead of looking at pairs of services or relying on generated code, tools like Nimbus build a comprehensive graph of your entire system. By statically analyzing code across all relevant repositories (and potentially infrastructure definitions), they map out services, APIs, data schemas, function calls, and message flows.
The Magic Moment: You, the UserService developer, rename user_email to emailAddress. As you prepare your Pull Request (or even while typing in your IDE), Nimbus analyzes the potential impact across the entire system graph. It flags not only the OrderService and NotificationService but also surfaces the incompatible usage in the long-forgotten ReportingService. It shows you exactly which downstream consumers will break before your change merges.
Pros:
- Finds all impacted consumers, even unknown or undocumented ones.
- Catches issues before tests are written or contracts need to run (true shift-left).
- Integrates directly into the developer workflow (IDE feedback, PR checks).
- Language-agnostic analysis (based on understanding interactions, not just language types).
- Can potentially flag impacts beyond APIs (e.g., direct database reads, message queue consumers).
Cons: Effectiveness hinges on the accuracy and completeness of the static analysis model and the system graph. May need complementary runtime checks for verifying complex, dynamic runtime behaviors.
Layering Your Defenses for True Confidence
These strategies aren't mutually exclusive; they're complementary layers of defense:
- Typed SDKs: Provide excellent first-line defense and DX within a consistent language stack.
- Contract Tests: Crucial for verifying behavior and ensuring compatibility between critical, known service pairs, especially across language boundaries.
- Integration Tests: Useful for validating user paths and complex interactions across multiple services, catching timing issues and boundary problems that only emerge in realistic environments.
- Impact Analysis (Nimbus): The essential system-wide safety net that proactively discovers unknown impacts, catches breaks before CI, and provides holistic confidence that your change won't cause unexpected downstream disasters.
Conclusion: Ship Fast and Safe
Stop relying on hope, manual checks, or post-deployment firefighting to manage integration risk. Layer your defenses, but recognize the unique power of understanding the full impact of your changes before they merge. Proactive, system-wide awareness, as provided by tools like Nimbus, is becoming essential for teams who need to move fast without constantly breaking things.
How does your team prevent integration bugs today? What strategies work well? What kinds of breakages still slip through the cracks? Let us know here!