Embrace Complexity: Practical Patterns for Distributed Systems (And How to Get There)
Microservices! The promised land of independent deployments, team autonomy, and glorious scalability. You dove in headfirst, breaking up the monolith, feeling the wind of agility in your hair... until you hit the wall. Suddenly, simple tasks become complex coordination nightmares, failures cascade unpredictably, and your frontend code looks like a tangled mess of API calls.
If this sounds familiar, you're not alone. The shift to distributed systems unlocks potential but also unleashes new kinds of complexity. Thankfully, you don't have to reinvent the wheel. Battle-tested architectural patterns exist not as academic exercises, but as survival guides forged in the fires of real-world distributed systems. Let's explore the journey from naive implementations to robust patterns, using a common e-commerce order flow as our guide.
The Naive Starting Point: The Synchronous Chain
Imagine you're building an online store. The first, most intuitive way to handle an order might look like this:
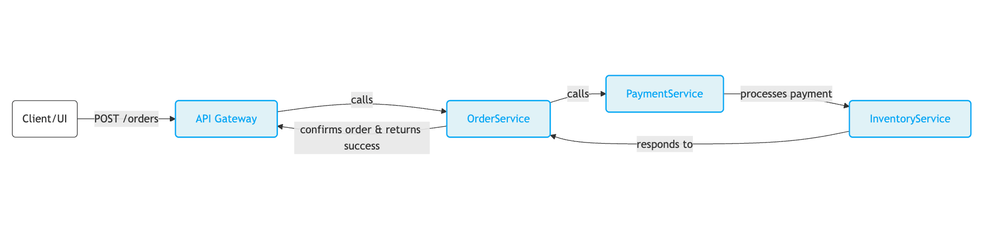
- API Gateway receives a
POST /ordersrequest. - It calls the
OrderServiceto create an order record. OrderServicethen callsPaymentServiceto process the payment.- If payment succeeds,
OrderServicecallsInventoryServiceto reserve the items. - If inventory is reserved,
OrderServiceconfirms the order and returns success to the gateway.
function handleOrder(request) {
order = createOrderRecord(request.details); // Step 2
paymentResult = paymentService.charge(order.id, request.paymentInfo); // Step 3 (Blocks)
if (paymentResult.isSuccess) {
inventoryResult = inventoryService.reserveItems(order.id, order.items); // Step 4 (Blocks)
if (inventoryResult.isSuccess) {
confirmOrder(order.id); // Step 5
return { status: "Success", orderId: order.id };
} else {
// Uh oh... payment succeeded, but inventory failed. Now what?
tryRollbackPayment(paymentResult.id); // Best effort? Risky!
cancelOrder(order.id);
throw new Error("Inventory unavailable");
}
} else {
cancelOrder(order.id);
throw new Error("Payment failed");
}
}This looks simple, right? It mimics a standard monolithic flow. But in a distributed world, this tight coupling is a ticking time bomb.
When Simplicity Bites Back: The Triggers for Change
This naive approach quickly runs into serious problems:
Pain Point 1: The Tangled Transaction & Data Inconsistency
What happens if PaymentService.charge succeeds, but InventoryService.reserveItems fails? You've taken the customer's money but can't fulfill the order. Rolling back the payment might fail, leaving the system in an inconsistent state. You need atomicity – either the whole order succeeds, or it fails cleanly. This leads us towards the Saga pattern.
Pain Point 2: The Domino Effect & Cascading Failures
The InventoryService is under heavy load and becomes slow or unresponsive. Because OrderService makes a blocking call to it, OrderService threads/processes pile up waiting. Soon, OrderService itself might become unresponsive, impacting all order operations, even those not needing inventory checks immediately. A failure in one service brings down others. This points towards the Circuit Breaker pattern.
Pain Point 3: Frontend Frankenstein & API Chaos
Your web app needs certain order details, the mobile app needs slightly different details plus shipping status, and a partner integration needs only basic confirmation. If all these clients hit the same granular OrderService, PaymentService, and InventoryService endpoints directly, they become chatty, potentially over-fetching data, and duplicating presentation logic. This suggests the need for API Gateways or Backends-for-Frontends (BFFs).
Evolution 1: From Chaos to Coordination -> The Saga Pattern
Instead of one giant, fragile transaction, a Saga coordinates a sequence of local transactions across services. Each local transaction updates its own service's data and publishes an event or calls the next step. Crucially, each step must also have a compensating transaction to undo its effects if a later step fails.
How it Works (Choreography Example - Event-Based):
OrderService: Creates order (status: PENDING), publishesOrderCreatedevent.PaymentService: Listens forOrderCreated, processes payment, publishesPaymentProcessed(orPaymentFailed) event.InventoryService: Listens forPaymentProcessed, reserves items, publishesInventoryReserved(orInventoryOutOfStock) event.OrderService: Listens forInventoryReservedorInventoryOutOfStock. Updates order status (CONFIRMED or FAILED). If failed after payment, it triggers a compensating action by publishing aRefundPaymentcommand/event.
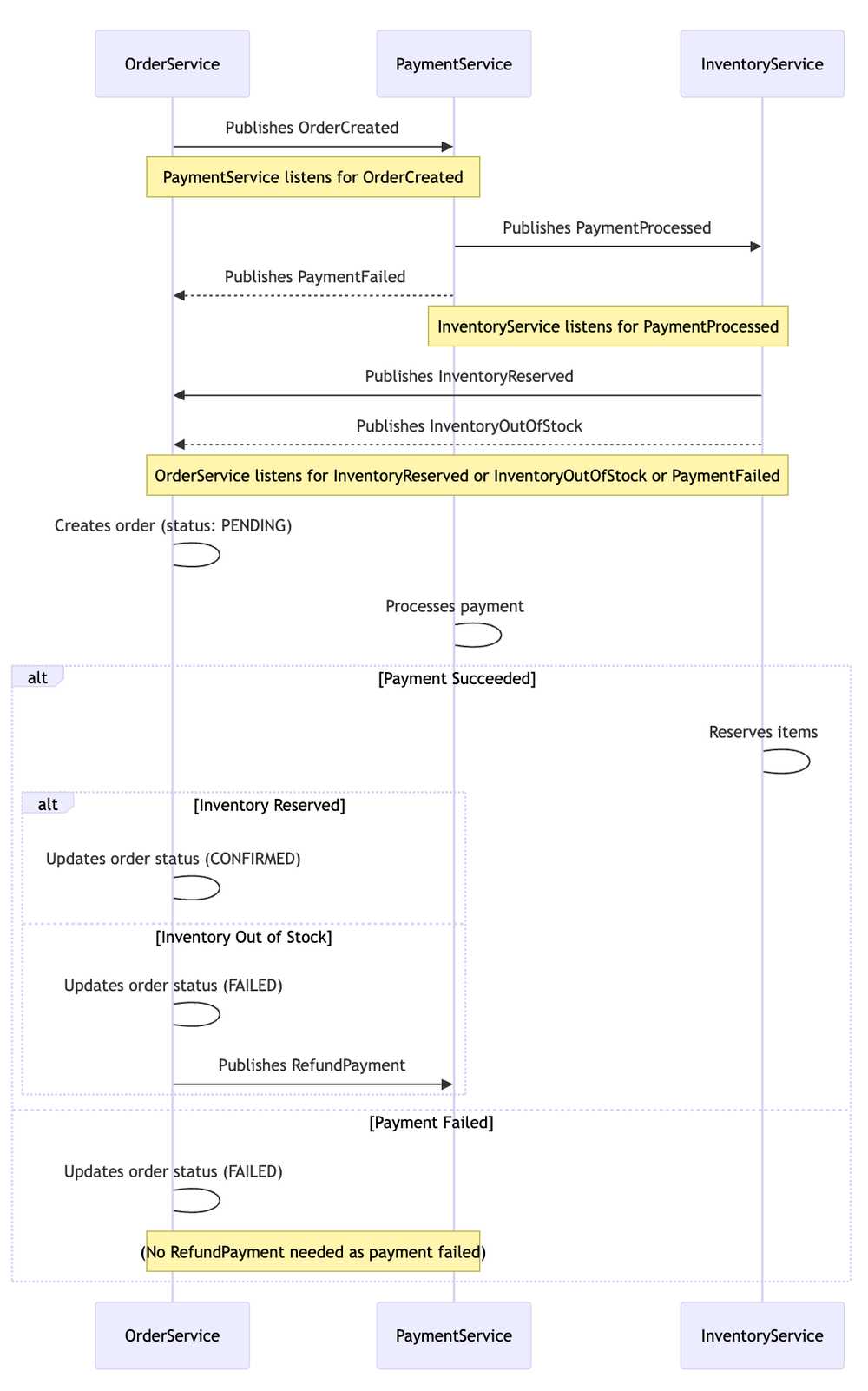
Benefit: No blocking calls between services. Each service manages its own transaction. Failure in one step triggers defined compensating actions, maintaining eventual consistency.
Note: Sagas can also be Orchestrated (a central coordinator manages the steps), which is sometimes simpler to track but introduces a potential single point of failure/bottleneck.
Evolution 2: From Fragile to Resilient -> The Circuit Breaker Pattern
To prevent cascading failures, you wrap risky cross-service calls (especially synchronous ones, if you still have them) in a Circuit Breaker.
How it Works:
- Closed: Calls pass through normally. If N calls fail in a row, trip the circuit to Open.
- Open: Calls fail immediately without hitting the network ("fail fast"). After a timeout, switch to Half-Open.
- Half-Open: Allow one test call through. If it succeeds, close the circuit. If it fails, trip back to Open.
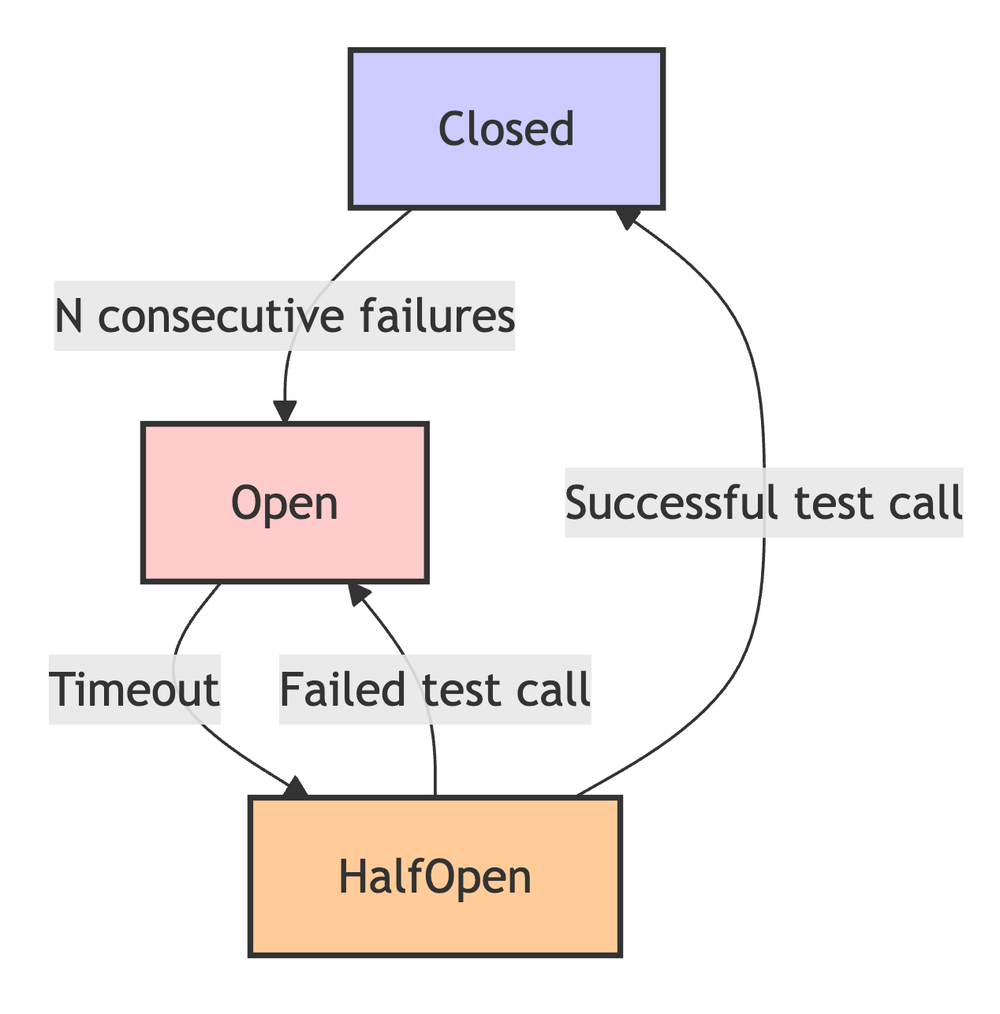
Illustration: The OrderService's call to InventoryService (if still synchronous, or perhaps to a critical synchronous lookup elsewhere) is wrapped. If InventoryService repeatedly fails, the breaker opens. Subsequent order attempts that need inventory might fail instantly ("Inventory unavailable, please try again later") without overloading the struggling InventoryService or the OrderService itself.
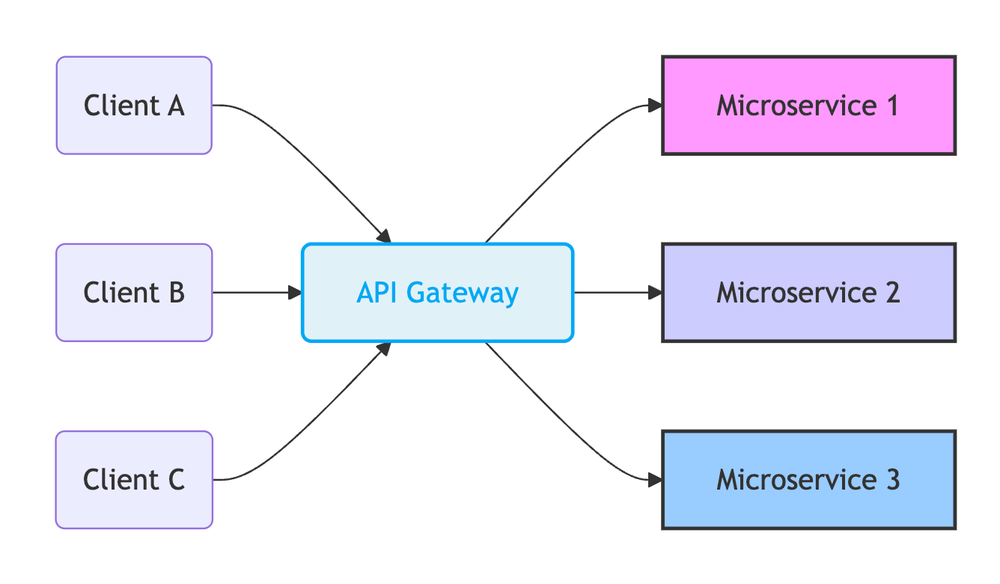
Evolution 3: From One-Size-Fits-All to Tailored -> API Gateway / BFF
Instead of exposing every microservice directly, introduce a facade layer.
API Gateway: A single entry point for all clients. Handles routing, authentication, rate limiting, SSL termination, potentially some light aggregation. Keeps the internal service topology hidden.
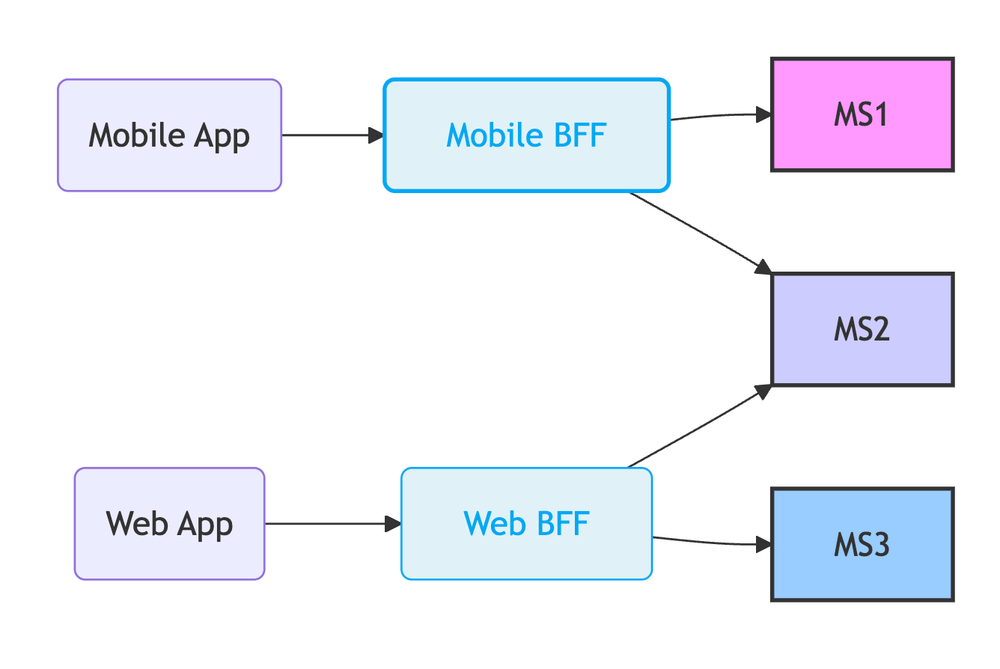
Backend-for-Frontend (BFF): A specialized API Gateway per client type. The Mobile BFF provides endpoints tailored exactly for the mobile app's needs, aggregating data from multiple backend services. The Web BFF does the same for the web app. Even with a single client type, this can be helpful for cross-cutting concerns, such as authorization, data-aggregation, or internationalization.
Comparison:
- Gateway: Simpler to manage initially, but can become bloated if serving too many diverse clients.
- BFF: Cleaner separation, optimized payloads per client, teams can own their BFF. Can lead to some code duplication if not managed well.
Prerequisite: System Sight
How do you choose the right pattern? How do you even know which services are involved in that order flow, especially after months of changes? Which calls are synchronous and risky? What data do different clients actually consume?
Implementing these patterns isn't just about knowing the pattern; it's about deeply understanding your system's actual structure and dependencies. Making architectural changes without this visibility is like performing surgery blindfolded.
Nimbus Connection: This is where understanding becomes critical. Tools that automatically map service interactions, visualize dependencies across repositories, and trace data flows – like Nimbus – provide the crucial visibility needed to:
- Identify which services participate in a business transaction (ideal candidates for Sagas).
- Pinpoint high-risk synchronous calls that need Circuit Breakers.
- Analyze data usage patterns to design effective API Gateways or BFFs.
- Confidently plan and execute the migration from naive implementations to robust patterns.
Conclusion: Evolve Intelligently
Distributed systems complexity is real, but manageable. These patterns provide proven solutions to common pains. The key is not just implementing them blindly, but understanding why they're needed and applying them strategically based on a clear view of your system's interactions. Don't just drown in complexity – understand it, apply the right patterns, and build resilient, evolvable systems.
What distributed system patterns have saved you? What challenges are you facing right now? Share your experiences in the comments!